RAG usage in Deev.ai
devv.ai 是如何构建高效的 RAG 系统的
如何让 LLM 使用外部知识库进行生成?之前的做法是在增加新的知识库后 fine-tuning,缺点是:每次更新知识都要重新 fine-tuning,带来巨大的训练成本。新的方案是 RAG,Retrieval Augmented Generation(检索增强生成),通过 prompt 的方式把新知识给到 LLM。三部分:
- LLM,GPT 或者开源的 LLaMA
- 固定不变的外部知识集合
- 当前场景下需要的外部知识
Notes:
- 外部知识库的存储,通过 OpenAI embedding 模型把知识数据向量化
- vector 向量数据库存储,Chroma、Pinecone、pgvector 等
- 优先做工原则:encoding 的时候做的越多,retrieve 的时候就能够更快更准
- 对数据做更多的细致处理,比如知识文档 chunk 分块,ranking 优化等
- 可以结合搜索引擎提高准确度
- 评估指标
- fluency,流畅性,生成的文本是否流畅连贯
- perceived utility,实用性,生成的内容是否有用
- citation recall,引文召回率,所生成的内容完全得到引文支持的比例
- citation precision,引文精度,引文中支持生成内容的比例

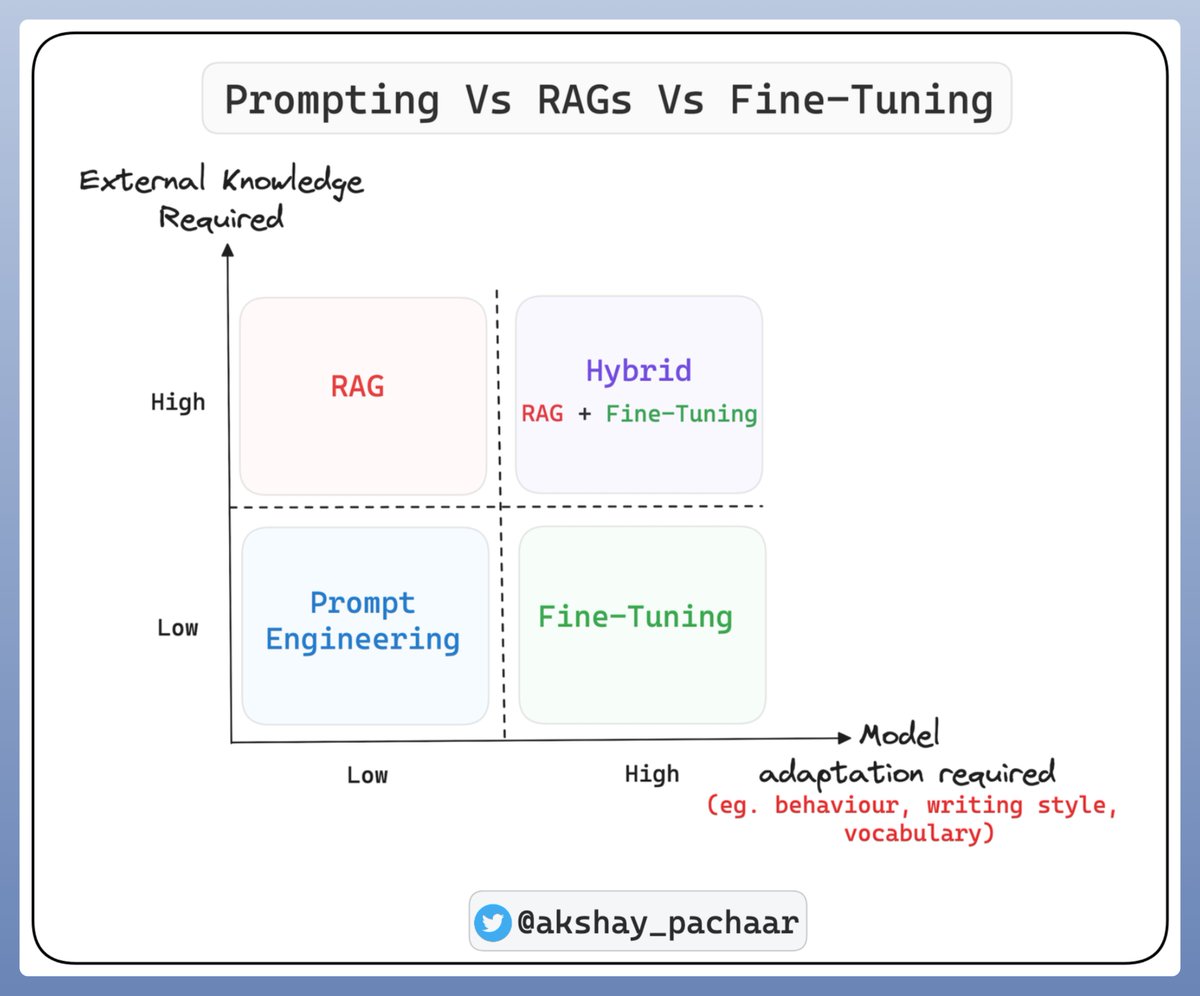
使用 LLM 的三种方式:Prompting, RAG, Fine-Tuning: RAG 用于扩展知识库,微调更多是关于改变结构(行为)而非知识。
Was this page helpful?