TIL-2504
- 取消微信的健康权限,比如微信运动读取步数,很明显提高微信打开时的 loading 速度
Bento Grids,「弁当」日语便当。Bento Grid 的特点是内容在卡片内,不容大小内容的卡片组合展示,类似「🍱」效果- 沉浸式翻译出的 PDF 识别 https://github.com/funstory-ai/BabelDOC
- nanobrowser 浏览器插件+AI=网页自动化
defaults write -g NSStatusItemSpacing -int 8decrease macOS’s status bar item spacing- Yak Shaving, Stay focused on the task at hand, and don’t shave that yak!
TIL-2503
- https://github.com/clice-project/clice language server for C/CPP LSP
- write concise essays, less than 500 words
- https://macos-defaults.com macOS defaults
<C-r>=on insert mode, will insert calculation result to buffer
TIL-2502
- FOFA/Shodan/hunter.qianxin etc search engine can be used to find unexpected exposed services, e.g.
port:9200for ES summarize your tool in a markdown table with availability, use this prompt to check ChatGPT’s levels, and re-enable some skills:g/foo/s/bar/baz/in vim can replacebarwithbazin the line containsfoo:vsame as:g!, inverse searching.:v/foo/dwill delete lines not containsfoo
TIL-2501
g?in vim will encode the selected TEXT in ROT13:let @a = @a . '@a', append macro call to make the macro recursive, run to the end of the file- https://instances.vantage.sh/, list and compare instances of AWS EC2/RDS etc
fc -Wwill savehistoryto~/.zsh_history. DO NOT RUNhistory -cTHAT WILL CLEAR THE HISTORY
Python's module-script utilities
The Python standard library offers many module-script utilities that can be used as command-line tools with the python -m syntax.
python -m webbrowser https://pym.dev/popen URL in default browserpython -m antigravityopen https://xkcd.com/353/python -m thisdisplay the Zen of Python (PEP 20)python -m __hello__printHello world!python -m http.serverstart a simple web serverpython -m json.toolvalidate and pretty-print JSON data from stdin or filepython -m calendardisplay a command-line calendarpython -m uuidgenerate an UUID stringpython -m sqlite3launch sqlite3 shellpython -m zipfile/gzip/tarfilelikezip/unziporgzip/gunziportarCLIpython -m base64likebase64CLIpython -m ftpliblikeftpCLIpython -m piprunpipto install third-party packagespython -m venvcreate an virtual environmentpython -m pydocshow documentation for given stringpython -m pdbrun Python Debuggerpython -m unittestrun unittest tests from modules or filepython -m timeittime a Python expressionpython -m sitedisplay current Python environment info likesys.pathpython -m platformdisplay OS informationpython -m encodings.rot_13encode/decode text byROT13cipher
More utilities and detailed explanation Python’s many command-line utilities
Apps by Sindre Sorhus
I’ve known @sindresorhus for a long time, used some of his Apps, and I’m a big fan of his work. Here are some of his Apps that I use:
Velja
Even though I prefer using Safari as my default browser, there are certain cases where I need to open a link like Google Docs in Arc because Safari is logged in with my personal account, while Arc is with my work account. In cases like this, I use Velja:
- Set Velja as the default browser and Safari as the primary one
- Use Arc as the alternative browser and click on links while pressing Fn for them to open in Arc
- Set rules for specific URLs to open in Arc, with URL matching
- Velja’s Safari extension also supports to open the current webpage in Arc
Velja is More Than a Browser Picker
Hyperduck
I need to send links from my iPhone to Mac for further reading, I have tried several methods:
- Tools like Pocket/Instapaper, which require opening the app on Mac to use
- Safari Reading List/iCloud Tabs, which I have been using for a long time before Hyperduck, but sometimes it does not sync well
Hyperduck does this job perfectly, shares link from Send to Mac, opens on Mac directly, and I don’t have to worry about syncing.
Thank you @sindresorhus for these great Apps! 🎉
29/02/24
From 29/02/08, this site has been running for 16 years.
Debounce and Throttle
- debounce 延迟生效,将间隔不超过设定时间的多次连续调用变成一次。如果在设定时间内连续两次调用,第一次调用会被取消,如果设定时间内没有再次调用,则生效执行
- throttle 节流阀,确保函数被多次连续调用时,在设定时间内最多只执行一次
- debounce 和 throttle 都可以用于降低事件处理函数的调用频率,以提高性能
- 在连续快速输入时,debounce 会等待最后一次输入后才执行,autocomplete 场景很有用
- throttle 会规律、稳定的执行,但是会有一定的延迟
Sequel Ace connected MySQL from SSH
After changed ~/.ssh/config, Ace still can’t connect to MySQL, we need to config Ace to grant access to .ssh files:
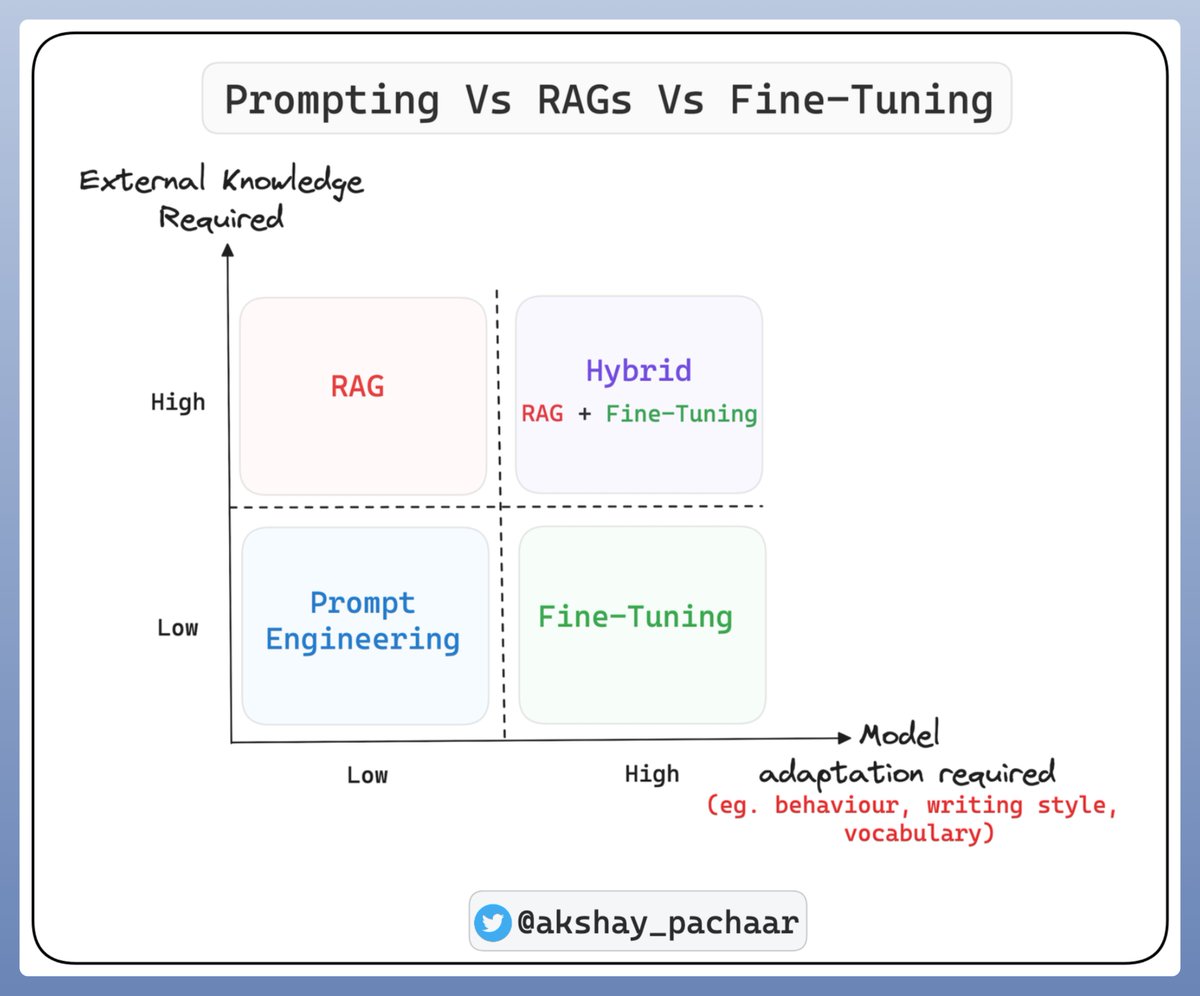
RAG usage in Deev.ai
devv.ai 是如何构建高效的 RAG 系统的
如何让 LLM 使用外部知识库进行生成?之前的做法是在增加新的知识库后 fine-tuning,缺点是:每次更新知识都要重新 fine-tuning,带来巨大的训练成本。新的方案是 RAG,Retrieval Augmented Generation(检索增强生成),通过 prompt 的方式把新知识给到 LLM。三部分:
- LLM,GPT 或者开源的 LLaMA
- 固定不变的外部知识集合
- 当前场景下需要的外部知识
Notes:
- 外部知识库的存储,通过 OpenAI embedding 模型把知识数据向量化
- vector 向量数据库存储,Chroma、Pinecone、pgvector 等
- 优先做工原则:encoding 的时候做的越多,retrieve 的时候就能够更快更准
- 对数据做更多的细致处理,比如知识文档 chunk 分块,ranking 优化等
- 可以结合搜索引擎提高准确度
- 评估指标
- fluency,流畅性,生成的文本是否流畅连贯
- perceived utility,实用性,生成的内容是否有用
- citation recall,引文召回率,所生成的内容完全得到引文支持的比例
- citation precision,引文精度,引文中支持生成内容的比例

使用 LLM 的三种方式:Prompting, RAG, Fine-Tuning: RAG 用于扩展知识库,微调更多是关于改变结构(行为)而非知识。